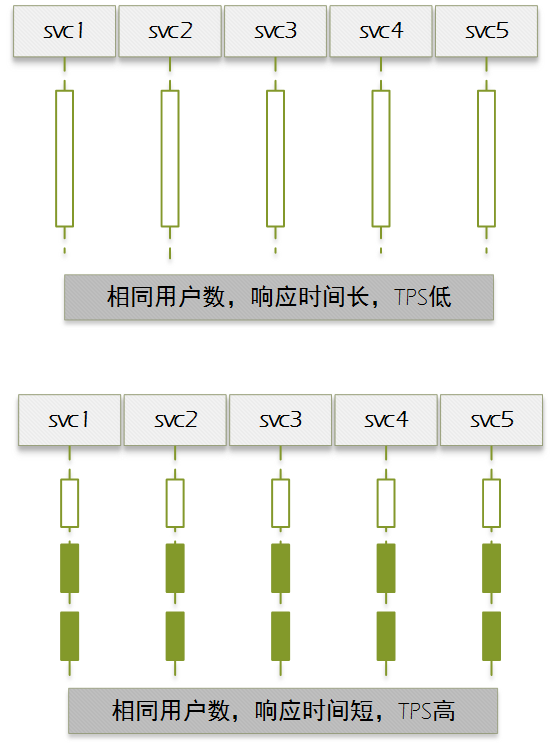
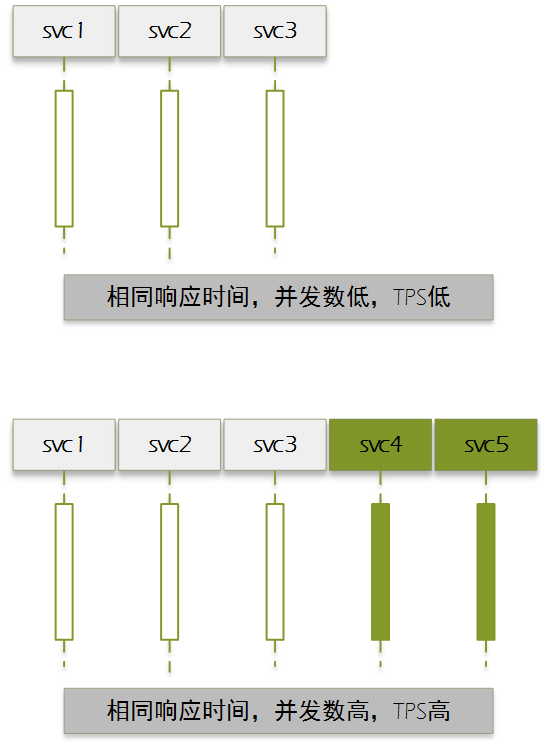
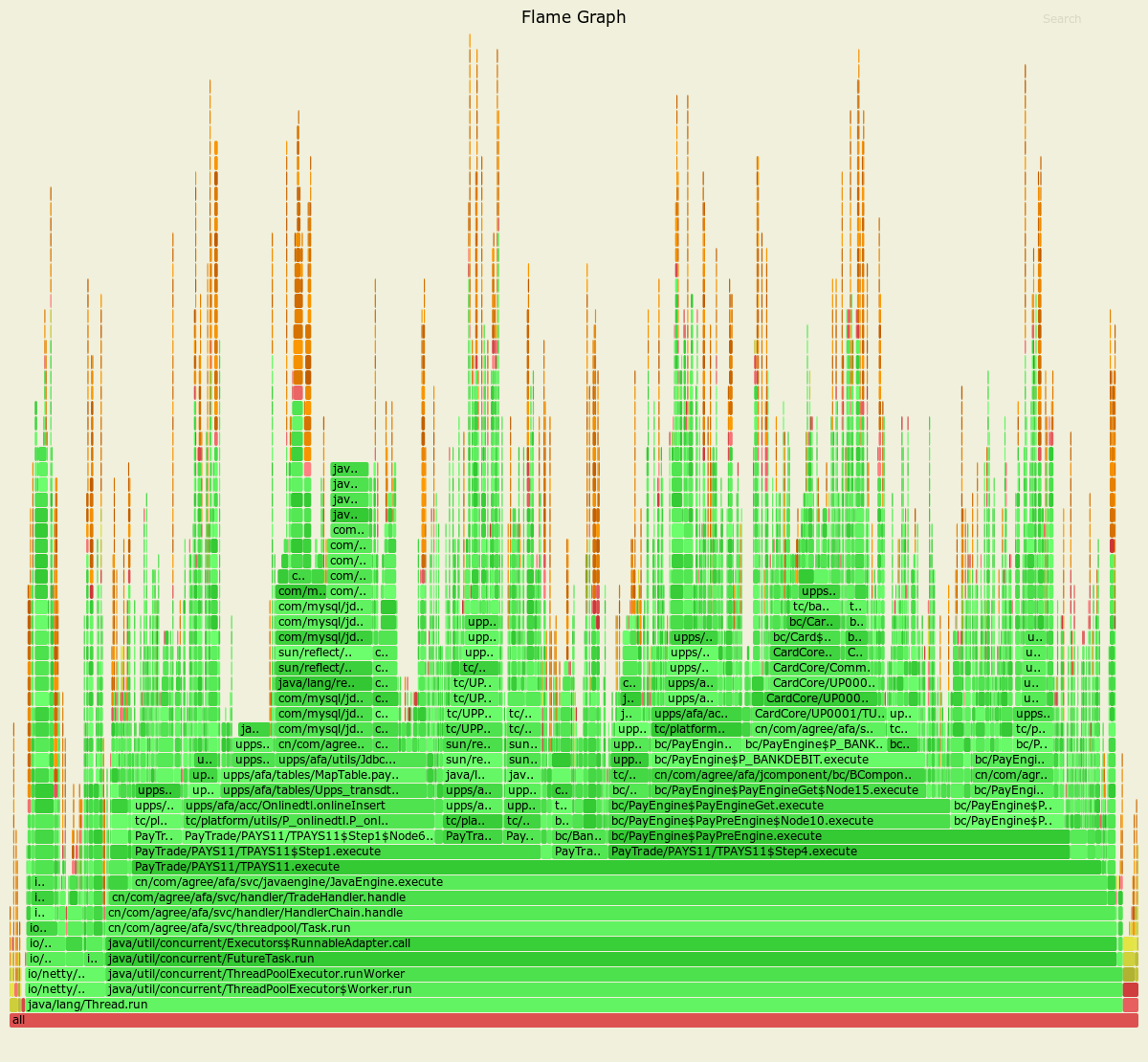
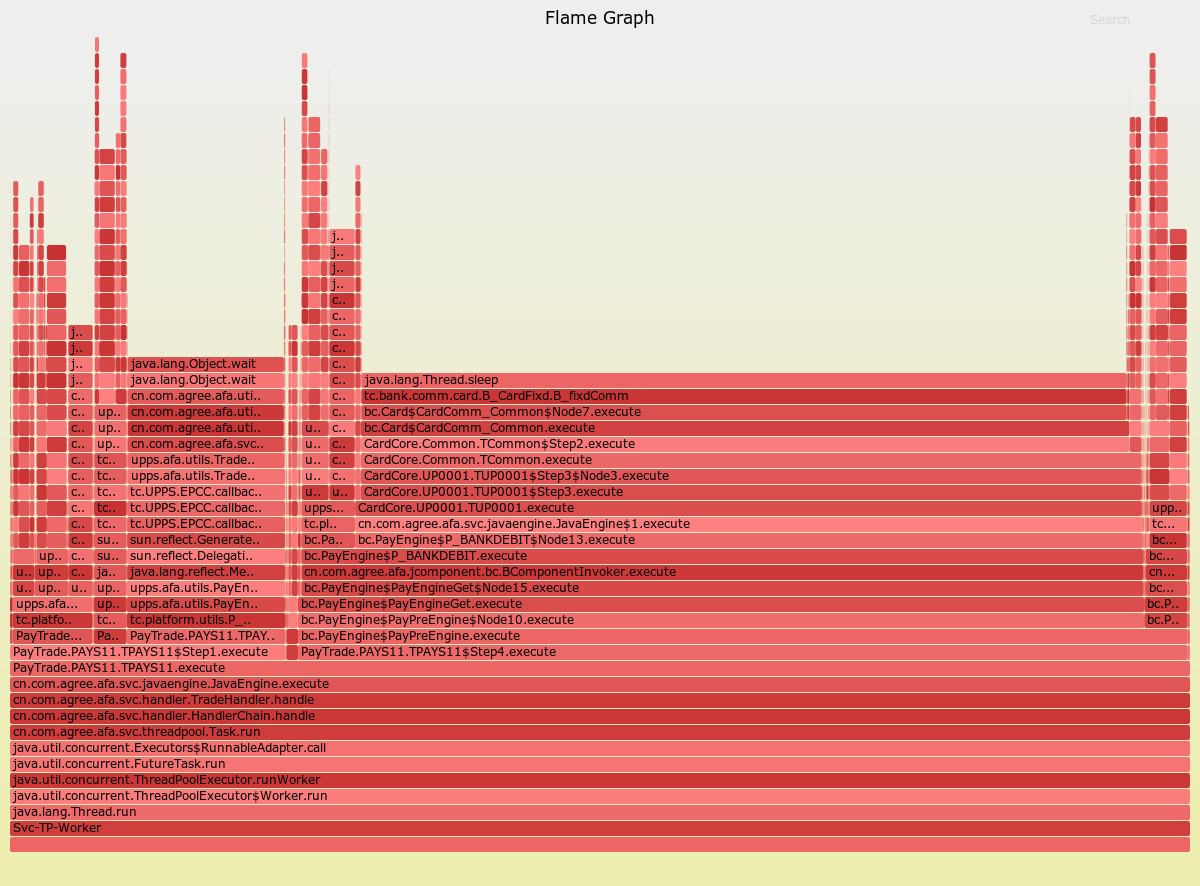
# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9268aef03fb9 ibmcom/db2 "/var/db2_setup/lib/…" 21 hours ago Up 22 seconds 22/tcp, 55000/tcp, 60006-60007/tcp, 0.0.0.0:50000->50000/tcp, :::50000->50000/tcp testdb
启停容器
# docker start testdb # docker stop testdb
进入容器
# docker exec -it testdb /bin/bash # su - db2inst1
查看实例版本及状态
$ db2level DB21085I This instance or install (instance name, where applicable: "db2inst1") uses "64" bits and DB2 code release "SQL11058" with level identifier "0609010F". Informational tokens are "DB2 v11.5.8.0", "s2209201700", "DYN2209201700AMD64", and Fix Pack "0". Product is installed at "/opt/ibm/db2/V11.5".
$ db2pd -
Database Member 0 -- Active -- Up 0 days 00:05:29 -- Date 2024-12-24-15.26.25.728524
启停实例
$ db2start 12/24/2024 15:27:23 0 0 SQL1063N DB2START processing was successful. SQL1063N DB2START processing was successful.
$ db2stop 12/24/2024 15:27:18 0 0 SQL1064N DB2STOP processing was successful. SQL1064N DB2STOP processing was successful.
测试数据库
$ db2 list db directory
System Database Directory
Number of entries in the directory = 1
Database 1 entry:
Database alias = TESTDB Database name = TESTDB Local database directory = /database/data Database release level = 15.00 Comment = Directory entry type = Indirect Catalog database partition number = 0 Alternate server hostname = Alternate server port number =
$ db2 connect to testdb
Database Connection Information
Database server = DB2/LINUXX8664 11.5.8.0 SQL authorization ID = DB2INST1 Local database alias = TESTDB
IBM Data Server Client Packages (11.5.*, All platforms) DSClients-ntx64-dsdriver-11.5.9000.352-FP000 v11.5.9_ntx64_dsdriver_EN.exe
下载安装后,需要将安装目录C:\Program Files\IBM\IBM DATA SERVER DRIVER\bin配置到Path环境变量,验证安装是否成功:
> db2level DB21085I This instance or install (instance name, where applicable: "*") uses "64" bits and DB2 code release "SQL11059" with level identifier "060A010F". Informational tokens are "DB2 v11.5.9000.352", "s2310270807", "DYN2310270807WIN64", and Fix Pack "0". Product is installed at "C:\PROGRA~1\IBM\IBMDAT~1" with DB2 Copy Name "IBMDBCL1".
测试数据库
> db2cli execsql -connstring "database=testdb;hostname=localhost;port=50000;uid=db2inst1;pwd=testdb" IBM DATABASE 2 Interactive CLI Sample Program (C) COPYRIGHT International Business Machines Corp. 1993,1996 All Rights Reserved Licensed Materials - Property of IBM US Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
> select count(*) from syscat.tables select count(*) from syscat.tables FetchAll: Columns: 1 1 437 FetchAll: 1 rows fetched.
DB2_ROOT = r"C:\Program Files\IBM\IBM DATA SERVER DRIVER"
重新编译会继续报另外一个错误
> python setup.py install Found DB2 with user-specified variable DB2 install path: "C:\Program Files\IBM\IBM DATA SERVER DRIVER" DB2 include path: "C:\Program Files\IBM\IBM DATA SERVER DRIVER\include" DB2 lib path: "C:\Program Files\IBM\IBM DATA SERVER DRIVER\lib" DB2 library: "db2cli" WARNING: It seems that you did not install the 'Application Development Kit'. Compilation may fail. running install running build running build_py creating build creating build\lib.win-amd64-2.7 copying DB2.py -> build\lib.win-amd64-2.7 running build_ext building '_db2' extension error: Unable to find vcvarsall.bat
> "E:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\vcvarsall.bat" x64 Setting environment for using Microsoft Visual Studio 2008 Beta2 x64 tools.
再次编译
重新编译通过,链接时报错
> python setup.py install Found DB2 with user-specified variable DB2 install path: "C:\Program Files\IBM\IBM DATA SERVER DRIVER" DB2 include path: "C:\Program Files\IBM\IBM DATA SERVER DRIVER\include" DB2 lib path: "C:\Program Files\IBM\IBM DATA SERVER DRIVER\lib" DB2 library: "db2cli" running install running build running build_py running build_ext building '_db2' extension
E:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\BIN\amd64\cl.exe /c /nologo /Ox /MD /W3 /GS- /DNDEBUG "-IC:\Program Files\IBM\IBM DATA SERVER DRIVER\include" -IC:\Python27\include -IC:\Python27\PC /Tc_db2_module.c /Fobuild\temp.win-amd64-2.7\Release\_db2_module.obj _db2_module.c
=============================================================================== Client information for the current copy (copy name: IBMDBCL1): ===============================================================================
...
=============================================================================== The validation is completed. ===============================================================================
$PID=12345 for i in {1..100} do jstack $PID >> time.raw sleep 0.01 done
最终采集到的数据:
"main" #1 prio=5 os_prio=0 tid=0x00007f2a0000f800 nid=0xaee waiting on condition [0x00007f2a09544000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
"main" #1 prio=5 os_prio=0 tid=0x00007f2a0000f800 nid=0xaee waiting on condition [0x00007f2a09544000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)